文章目录
两个问题
a.分析SQL的执行计划 : explain ,可以模拟SQL优化器执行SQL语句,从而让开发人员 知道自己编写的SQL状况
b.MySQL查询优化其会干扰我们的优化
执行计划
查询执行计划: explain +SQL语句
例如:
explain select * from COURSE;

id : 编号
select_type :查询类型
table :表
type :类型
possible_keys :预测用到的索引
key :实际使用的索引
key_len :实际使用索引的长度
ref :表之间的引用
rows :通过索引查询到的数据量
Extra :额外的信息
下面创建三张表来进行操作,进而解释上面的各种概念:
1、准备数据:
COURSE表:
create table course
(
cid int(3),
cname varchar(20),
tid int(3)
);
TeacherCard表:
create table teacherCard
(
tcid int(3),
tcdesc varchar(200)
);
TEACHER表:
create table teacher
(
tid int(3),
tname varchar(20),
tcid int(3)
);
------------------------------------------------------------
插入数据:
insert into course values(1,'java',1);
insert into course values(2,'html',1);
insert into course values(3,'sql',2);
insert into course values(4,'web',3);
insert into teacherCard values(1,'tzdesc') ;
insert into teacherCard values(2,'twdesc') ;
insert into teacherCard values(3,'tldesc') ;
insert into teacher values(1,'tz',1);
insert into teacher values(2,'tw',2);
insert into teacher values(3,'tl',3);
id:编号
查询课程编号为2 或 教师证编号为3 的老师信息
select t.* from teacher t,course c,teacherCard tc where
t.tid=c.tid and t.tcid=tc.tcid and(c.cid=2 or tc.tcid=3);

可以得到如下结论:
1、id: id值相同,从上往下 顺序执行。
可以发现表是按照表中的数量进行排序的
t3条-tc3条-c4条数据;
表的执行顺序 因数量的个数改变而改变的
原因: 笛卡儿积
比如改变三张表中的数据量为: tc3–c4-t6
则执行顺序为tc->c->t
假如:三张表的数据量为4 3 2;
a b c
4 3 2
如果按C B A的顺序执行:
2*3*4=6*4=24
如果按照A B C的顺序执行:
3*4*2=12*2=24
可以发现虽然结果没变,但是过程中处理的数据量变了,第一种处理的数据量要小
一点。
所以得出以下结论:数据小的表 优先查询。
2、id值不同:id值越大越优先查询 (本质:在嵌套子查询时,先查内层 再查外层)
查询教授SQL课程的老师的描述(desc)
explain select tc.tcdesc from teacherCard tc,course c
,teacher t where c.tid = t.tid
and t.tcid = tc.tcid and c.cname = 'sql' ;
将以上 多表查询 转为子查询形式:
explain select tc.tcdesc from teacherCard tc where tc.tcid =
(select t.tcid from teacher t where t.tid =
(select c.tid from course c where c.cname = 'sql')
);

3、id值有相同,又有不同: id值越大越优先;id值相同,从上往下 顺序执行
还是上面的语句改成子查询+多表:
explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid
and t.tid = (select c.tid from course c where cname = 'sql') ;

select_type:查询类型
PRIMARY:包含子查询SQL中的 主查询 (最外层)
SUBQUERY:包含子查询SQL中的 子查询 (非最外层)
simple:简单查询(不包含子查询、union)
derived:衍生查询(使用到了临时表)
a.在from子查询中只有一张表
explain select cr.cname
from ( select * from course where tid in (1,2) ) cr ;
b.在from子查询中, 如果有table1 union table2 ,则table1 就是derived,table2就是union
explain select cr.cname
from ( select * from course where tid = 1 union select *
from course where tid = 2 ) cr ;
union:上例情况B
union result :告知开发人员,那些表之间存在union查询
type:索引类型、类型
system>const>eq_ref>ref>range>index>all
从左往右代表情况越不理想,一般优化目标到达ref和range,system,const只是理想情况。
system(忽略):
只有一条数据的系统表 ;或 衍生表只有一条数据的主查询
const:
仅仅能查到一条数据的SQL ,用于Primary key 或unique索引
(类型 与索引类型有关:就是假如你只查到了一条数据,但是你不是根据Primary key 或unique索引 来查询的那也达不到const)
1、首先建表
create table test01
(
tid int(3),
tname varchar(20)
);
insert into test01 values(1,'a') ;
2、增加索引
create index test01_index on test01(tid) ;
explain select tid from test01 where tid =1 ;

eq_ref:
唯一性索引:对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多 、不能0)常见于唯一索引 和主键索引。
alter table teacherCard add constraint pk_tcid primary key(tcid);
alter table teacher add constraint uk_tcid unique index(tcid) ;
explain select t.tcid from teacher t,teacherCard tc where t.tcid = tc.tcid ;

ref:
非唯一性索引,对于每个索引键的查询,返回匹配的所有行(0,多)
准备数据:
insert into teacher values(4,'tz',4) ;
insert into teacherCard values(4,'tz222');
测试:
alter table teacher add index index_name (tname) ;
explain select * from teacher where tname = 'tz';

range:
检索指定范围的行 ,where后面是一个范围查询(between ,> < >=, 特殊:in有时候会失效 ,从而转为 无索引all)
alter table teacher add index tid_index (tid) ;
explain select t.* from teacher t where t.tid in (1,2) ;
explain select t.* from teacher t where t.tid <3 ;

index:
查询全部索引中数据。
explain select tid from teacher ;
--tid 是索引, 只需要扫描索引表,不需要所有表中的所有数据

all:
查询全部表中的数据。
explain select cid from course ;
--cid不是索引,需要全表所有,即需要所有表中的所有数据

possible_keys :可能用到的索引,是一种预测,不准。
alter table course add index cname_index (cname);
explain select t.tname ,tc.tcdesc from teacher t,teacherCard
tc where t.tcid= tc.tcidand t.tid =
(select c.tid from course c where cname = 'sql') ;

如果 possible_key/key是NULL,则说明没用索引如果 possible_key/key都是NULL,则说明没用索引
key :实际使用到的索引
key_len :索引的长度 ;
作用:用于判断复合索引是否被完全使用 (a,b,c)。
准备数据:
create table test_kl
(
name char(20) not null default ''
);
alter table test_kl add index index_name(name) ;
explain select * from test_kl where name ='' ;
-- key_len :60

明明name是char(20)但是key_len 是60。这是因为在utf8:1个字符占3个字节。
alter table test_kl add column name1 char(20) ;
--name1可以为null
alter table test_kl add index index_name1(name1) ;
explain select * from test_kl where name1 ='' ;

此时可以看到key_len 为61.这是因为如果索引字段可以为Null,则会使用1个字节用于标识。
增加一个复合索引 :
alter table test_kl add index name_name1_index (name,name1) ;
explain select * from test_kl where name1 = '' ; --121
explain select * from test_kl where name = '' ; --60
key_len 为60的情况:和之前utf8一样,不用多讲。
key_len 为121的情况:是因为首先用了name索引,再用了name1,二者长度之和。
alter table test_kl add column name2 varchar(20) ;
--可以为Null
alter table test_kl add index name2_index (name2) ;
explain select * from test_kl where name2 = '' ;
--63
20*3=60 + 1(null) +2(用2个字节 标识可变长度) =63
PS:
1、在mysql中char与varchar的区别呢,都是用来存储字符串的,只是他们的保存方式不一样罢了,char有固定的长度,而varchar属于可变长的字符类型。
2、
utf8:1个字符3个字节
gbk:1个字符2个字节
latin:1个字符1个字节
ref : 注意与type中的ref值区分。
作用: 指明当前表所 参照的 字段。
select ....where a.c = b.x ;(其中b.x可以是常量,const)
alter table course add index tid_index (tid) ;
explain select * from course c,teacher t where c.tid = t.tid
and t.tname ='tw' ;
rows: 被索引优化查询的 数据个数 (实际通过索引而查询到的 数据个数)
explain select * from course c,teacher t where c.tid = t.tid
and t.tname = 'tz' ;


Extra:额外的字段
(i).using filesort : 性能消耗大;需要“额外”的一次排序(查询) 。常见于 order by 语句中。
准备数据:
create table test02
(
a1 char(3),
a2 char(3),
a3 char(3),
index idx_a1(a1),
index idx_a2(a2),
index idx_a3(a3)
);
explain select * from test02 where a1 ='' order by a2 ;
--using filesort

语句中查询是根据a1来的,但是需要根据a2排序,所以得再把a2查一遍再进行排序。
总之:
对于单索引, 如果排序和查找是同一个字段,则不会出现using filesort;如果排序和查找不是同一个字段,则会出现using filesort;
避免: where哪些字段,就order by那些字段
复合索引:不能跨列(最佳左前缀)
drop index idx_a1 on test02;
drop index idx_a2 on test02;
drop index idx_a3 on test02;
alter table test02 add index idx_a1_a2_a3 (a1,a2,a3) ;
explain select *from test02 where a1='' order by a3 ;
--using filesort
explain select *from test02 where a2='' order by a3 ;
--using filesort
explain select *from test02 where a1='' order by a2 ;
explain select *from test02 where a2='' order by a1 ;
--using filesort
所谓的跨列就是说复合索引(a1,a2,a3)从左往右,a1,a2不算跨列,a1,a3算跨列。只要跨列就会出现–using filesort。
避免: where和order by 按照复合索引的顺序使用,不要跨列或无序使用。
(ii). using temporary:性能损耗大 ,用到了临时表。一般出现在group by 语句中。
explain select a1 from test02 where a1 in ('1','2','3')
group by a1 ;
explain select a1 from test02 where a1 in ('1','2','3')
group by a2 ; --using temporary
避免:查询那些列,就根据那些列 group by .
(iii). using index :性能提升; 索引覆盖(覆盖索引)。
原因:不读取原文件,只从索引文件中获取数据 (不需要回表查询)
只要使用到的列 全部都在索引中,就是索引覆盖using index
例如:test02表中有一个复合索引(a1,a2,a3)
explain select a1,a2 from test02 where a1='' or a2= '' ;
--using index
所查询的数据都在索引中。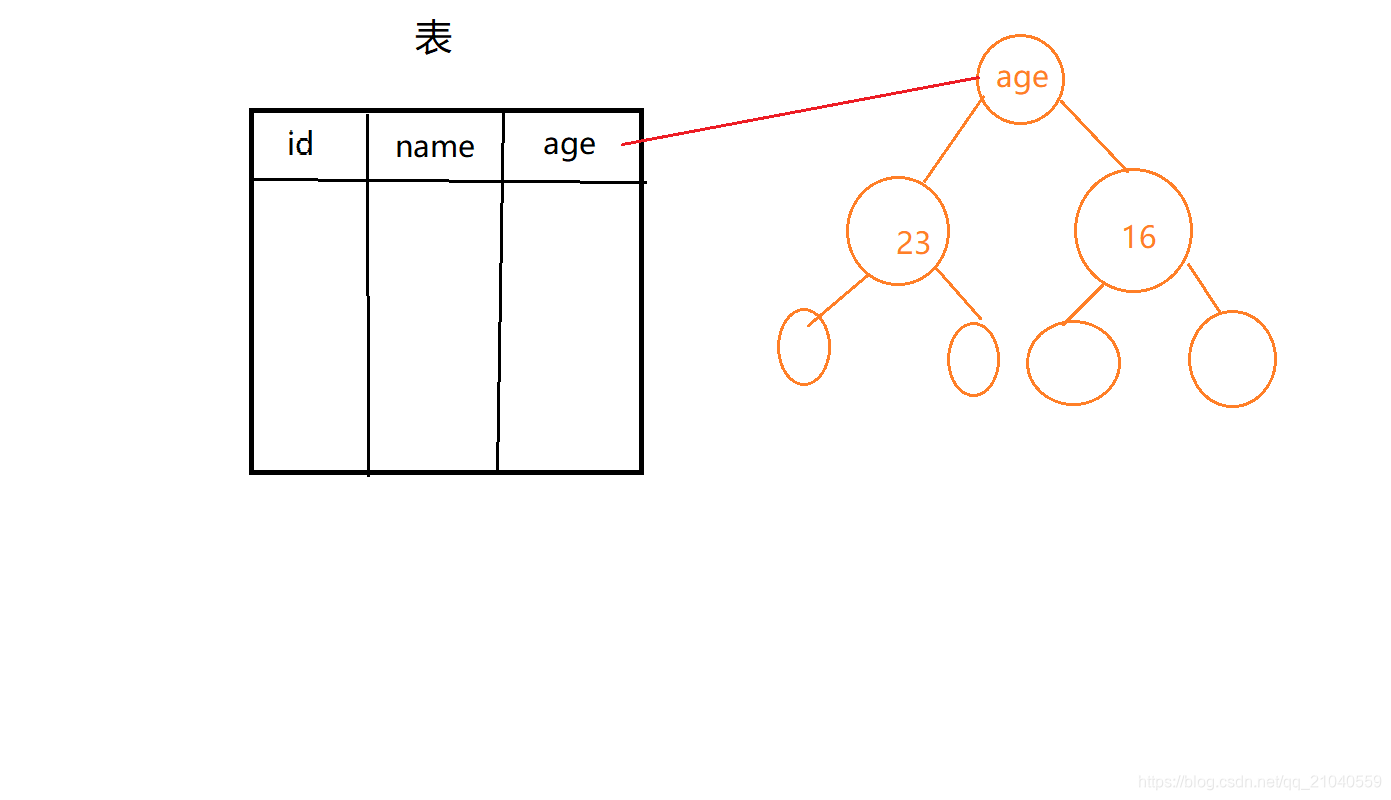
比如只查询age,那么所有的age都在索引中,只需要去索引中查找就行了,不需要回表查询。
如果用到了索引覆盖(using index时),会对 possible_keys和key造成影响:
a.如果没有where,则索引只出现在key中;
b.如果有where,则索引 出现在key和possible_keys中。
explain select a1,a2 from test02 where a1='' or a2= '' ;
explain select a1,a2 from test02 ;
(iii).using where (需要回表查询)
假设age是索引列
但查询语句select age,name from …where age =…,此语句中必须回原表查Name,因此会显示using where.
(iv). impossible where : where子句永远为false
例如
explain select * from test02 where a1=‘x’ and a1=‘y’ ;



