RabbitMQ的集群
普通集群(副本集群)
All data/state required for the operation of a RabbitMQ broker is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes. To replicate queues across nodes in a cluste
默认情况下:RabbitMQ代理操作所需的所有数据/状态都将跨所有节点复制。这方面的一个例外是消息队列,默认情况下,消息队列位于一个节点上,尽管它们可以从所有节点看到和访问(普通集群队列只存在于master上,但是消费者也能从slave上面访问到,这是因为消费者如果是和slave对接的话,slave就会找master要它队列中的信息。)
架构图
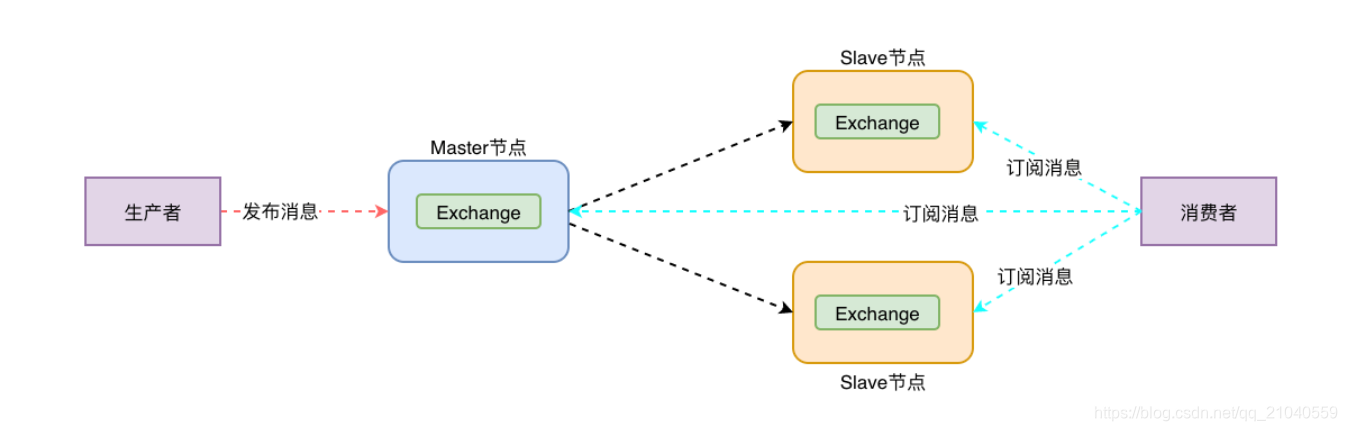
核心解决问题: 当集群中某一时刻master节点宕机,可以对Quene中信息,进行备份
集群搭建
0.集群规划
node1: 192.168.80.33 mq1 master 主节点
node2: 192.168.80.34 mq2 repl1 副本节点
node3: 192.168.80.35 mq3 repl2 副本节点1.克隆三台机器主机名和ip映射
vim /etc/hosts加入:
10.15.0.3 mq1
10.15.0.4 mq2
10.15.0.5 mq3修改节点名后要重启服务器 才能够生效
node1: vim /etc/hostname 修改: mq1.localdomain
node2: vim /etc/hostname 修改: mq2.localdomain
node3: vim /etc/hostname 修改: mq3.localdomain注意是修改这个位置!!不是重新添加一行2.三个机器安装rabbitmq,并同步cookie文件,在node1上执行:
先把三台机器:vim /etc/hosts
然后同步erlang.cookie:(在mq1上执行)
scp /var/lib/rabbitmq/.erlang.cookie root@mq2:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie root@mq3:/var/lib/rabbitmq/
注意:
3.查看cookie是否一致:
node1: cat /var/lib/rabbitmq/.erlang.cookie
node2: cat /var/lib/rabbitmq/.erlang.cookie
node3: cat /var/lib/rabbitmq/.erlang.cookie4.后台启动rabbitmq所有节点执行如下命令,启动成功访问管理界面:
rabbitmq-server -detached (后台启动看不到WEB界面)
systemctl start rabbit…(看得到)5.在node2和node3执行加入集群命令:
1.关闭 rabbitmqctl stop_app
2.加入集群 rabbitmqctl join_cluster rabbit@mq1《必须在mq1启动着的状态下执行》(加入主机名为mq1的主机,注意@后面不是IP地址,所以之前的主机名映射就很重要。)
3.启动服务 rabbitmqctl start_app6.查看集群状态,任意节点执行:
rabbitmqctl cluster_status7.如果出现如下显示,集群搭建成功:
Cluster status of node rabbit@mq3 …
[{nodes,[{disc,[rabbit@mq1,rabbit@mq2,rabbit@mq3]}]},
{running_nodes,[rabbit@mq1,rabbit@mq2,rabbit@mq3]},
{cluster_name,<<“rabbit@mq1”>>},
{partitions,[]},
{alarms,[{rabbit@mq1,[]},{rabbit@mq2,[]},{rabbit@mq3,[]}]}]8.登录管理界面,展示如下状态:

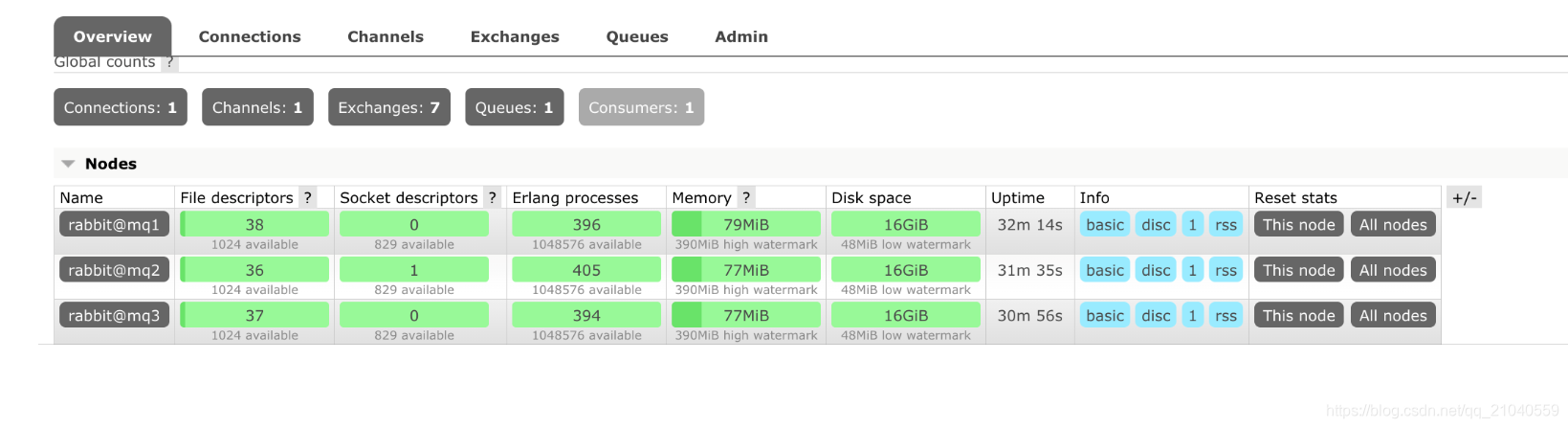
此模式下在mq1上建立一个队列,然后2 3 都能看到。但是当1宕机后,2、3的队列也会处于down状态无法使用。
镜像集群(普通集群模式配置策略就可以成为镜像集群模式)
This guide covers mirroring (queue contents replication) of classic queues
By default, contents of a queue within a RabbitMQ cluster are located on a single node (the node on which the queue was declared). This is in contrast to exchanges and bindings, which can always be considered to be on all nodes. Queues can optionally be made mirrored across multiple nodes.
镜像队列机制就是将队列在三个节点之间设置主从关系,消息会在三个节点之间进行自动同步,且如果其中一个节点不可用,并不会导致消息丢失或服务不可用的情况,提升MQ集群的整体高可用性
架构图
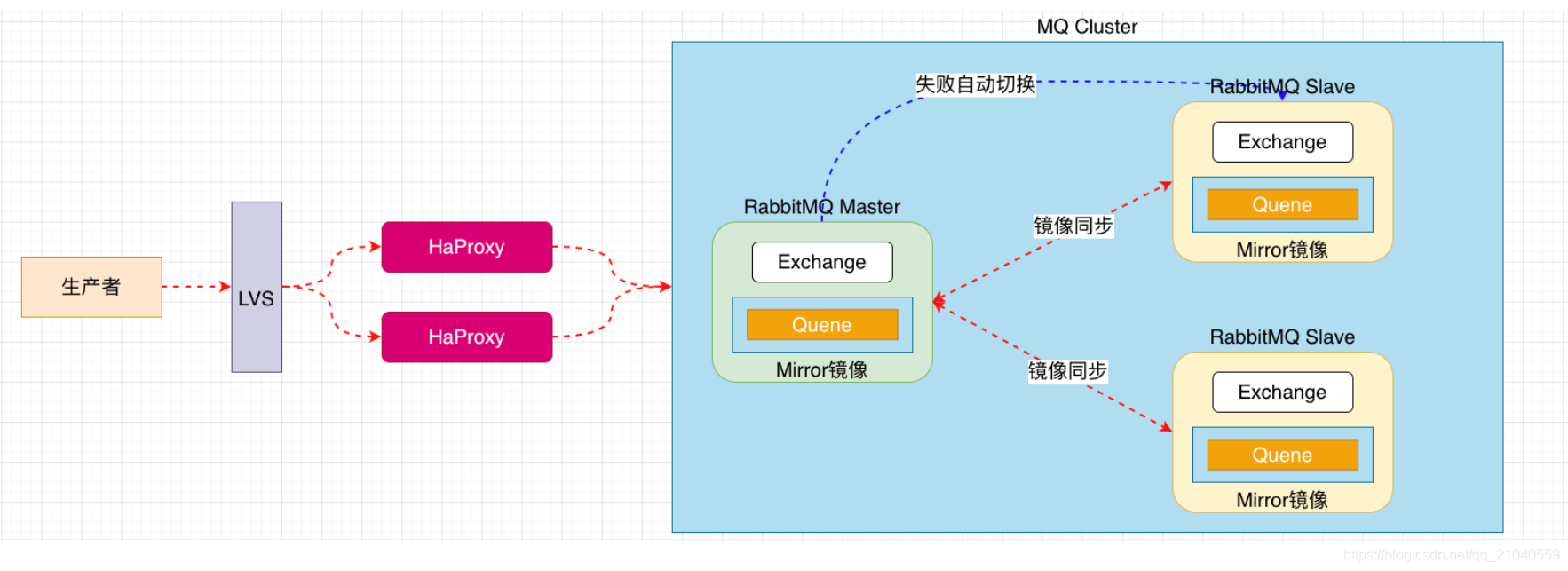
配置集群架构
0.策略说明
1.查看当前策略
rabbitmqctl list_policies2.添加策略
rabbitmqctl set_policy ha-all ‘^hello’ ‘{“ha-mode”:“all”,“ha-sync-mode”:“automatic”}’
说明:策略正则表达式为 “^” 表示所有匹配所有队列名称 ^hello:匹配hello开头队列3.删除策略
rabbitmqctl clear_policy ha-all4.测试集群
同样在mq1上建立队列hello,然后让mq1宕机,发现2、3的队列还能正常使用




