redis五种数据结构底层实现
String
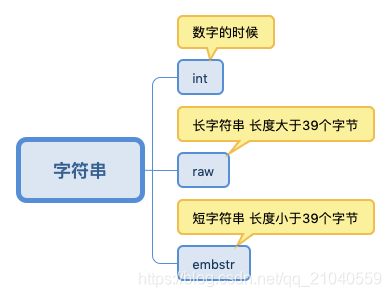
其中:embstr和raw都是由SDS动态字符串构成的。唯一区别是:raw是分配内存的时候,redisobject和 sds 各分配一块内存,而embstr是redisobject和raw在一块儿内存中。
list

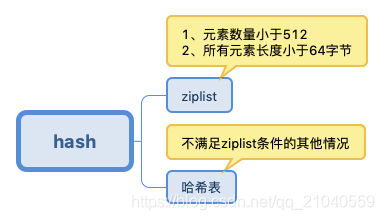
hash
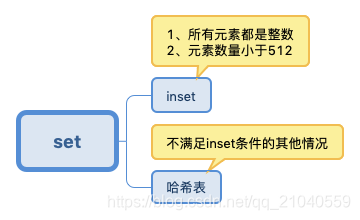
set
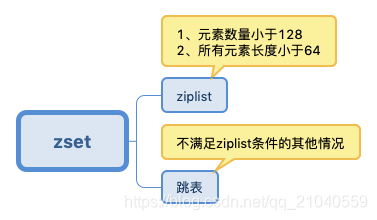
zset
对应结构的讲解
动态字符串SDS
SDS是”simple dynamic string”的缩写。
redis中所有场景中出现的字符串,基本都是由SDS来实现的
- 所有非数字的key。例如set msg “hello world” 中的key msg.
- 字符串数据类型的值。例如`` set msg “hello world”中的msg的值”hello wolrd”
- 非字符串数据类型中的“字符串值”。例如RPUSH fruits “apple” “banana” “cherry”中的”apple” “banana” “cherry”
SDS图示: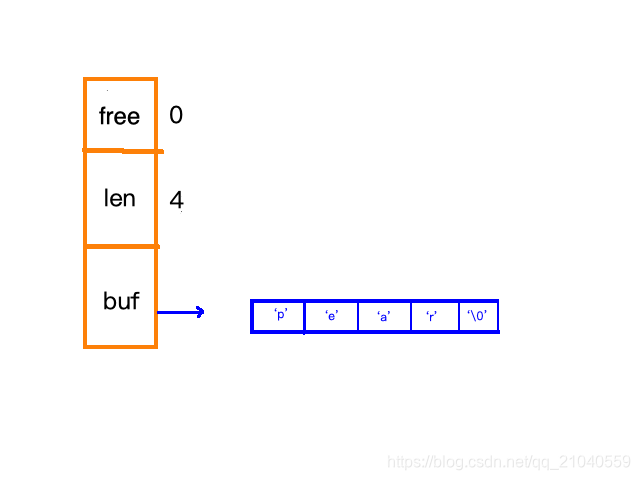
free:还剩多少空间
len:字符串长度
buf:存放的字符数组
空间预分配
为减少修改字符串带来的内存重分配次数,sds采用了“一次管够”的策略:
- 若修改之后sds长度小于1MB,则多分配现有len长度的空间
- 若修改之后sds长度大于等于1MB,则扩充除了满足修改之后的长度外,额外多1MB空间
图解
惰性空间释放
为避免缩短字符串时候的内存重分配操作,sds在数据减少时,并不立刻释放空间。
int
就是redis中存放的各种数字
包括下面这种,故意加引号“”的
双向链表
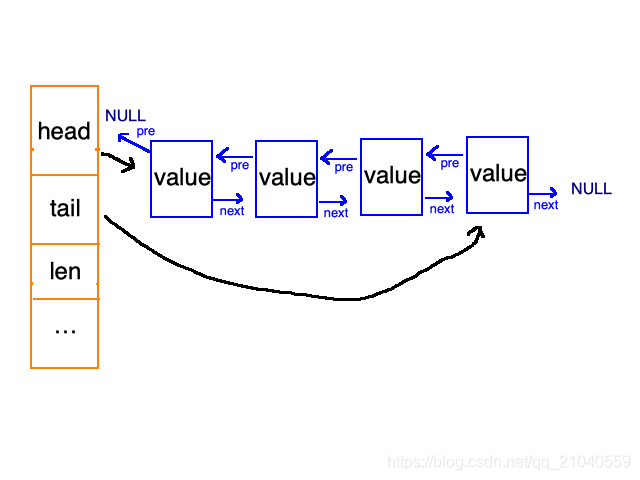
分两部分,一部分是“统筹部分”:橘黄色,一部分是“具体实施方“:蓝色。
主体”统筹部分“:
- head指向具体双向链表的头
- tail指向具体双向链表的尾
- len双向链表的长度
具体”实施方”:普通的双向链表结构,有前指针后指针
由list和listNode两个数据结构构成。
ziplist
压缩列表。
redis的列表键和哈希键的底层实现之一。此数据结构是为了节约内存而开发的。和各种语言的数组类似,它是由连续的内存块组成的,这样一来,由于内存是连续的,就减少了很多内存碎片和指针的内存占用,进而节约了内存。
然后上图中的entry的结构是这样的:

哈希表
哈希表的制作方法一般有两种,一种是:开放寻址法,一种是拉链法。redis的哈希表的制作使用的是拉链法。
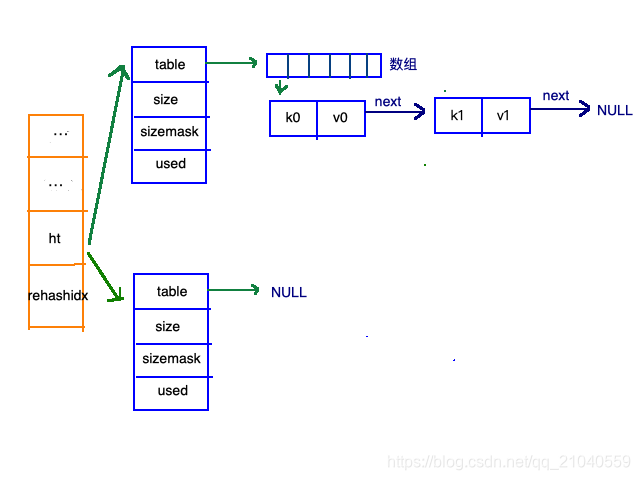
新建key的过程:
假如重复了就用拉链法。
再来看看哈希表总体图中左边橘黄色的“统筹”部分,其中有两个关键的属性:ht和rehashidx。
ht是一个数组,有且只有俩元素ht[0]和ht[1];其中,ht[0]存放的是redis中使用的哈希表,而ht[1]和rehashidx和哈希表的rehash有关。
rehash指的是重新计算键的哈希值和索引值,然后将键值对重排的过程。
加载因子(load factor) = ht[0].used / ht[0].size。
intset
是集合键的底层实现方式之一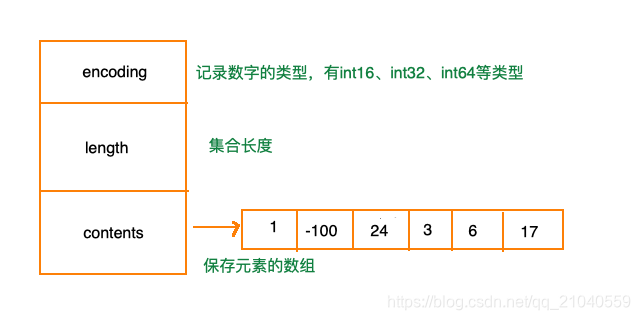
跳表
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
跳表的数据结构: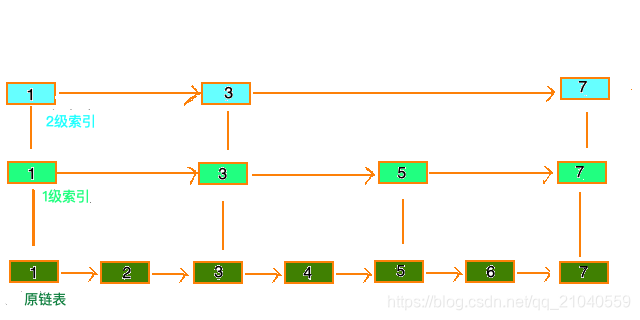
更详细一点: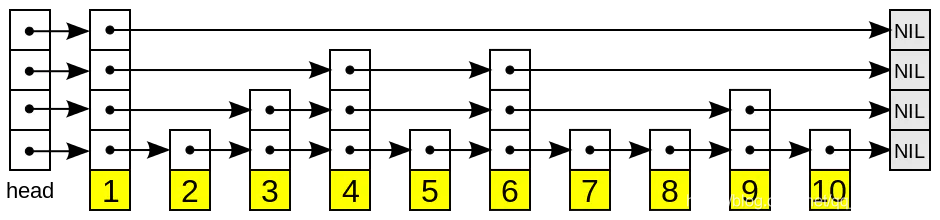
性质
- 由很多层结构组成
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节
- 最底层的链表包含了所有的元素
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集)
- 链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;



