Linux的IO模式
本文讨论的背景是Linux环境下的network IO。
概念说明
在进行解释之前,首先要说明几个概念:
- 进程的阻塞
- 文件描述符
- 缓存 I/O
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的 该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
IO模式
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
用于举例的故事背景:
老李去买火车票,三天后买到一张退票。参演人员(老李,黄牛,售票员,快递员),往返车站耗费1小时。
阻塞 I/O(BIO)
在linux中,默认情况下所有的socket都是blocking,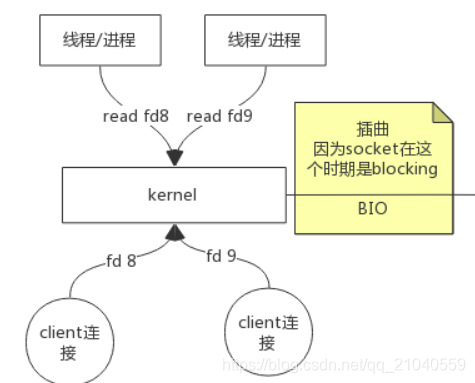
我要read fd8,如果没完成,那么下一个操作就要一直阻塞,无法进行。
老李去火车站买票,排队三天买到一张退票。
耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
非阻塞 I/O(NIO)
linux下,可以通过设置socket使其变为non-blocking。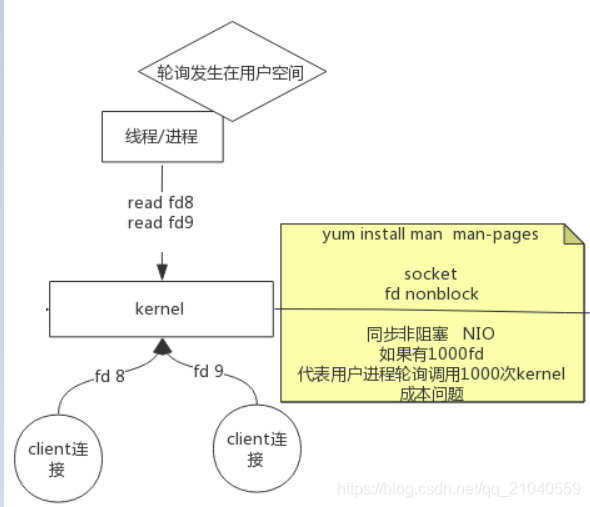
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的系统调用,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,NIO的特点是用户进程需要不断的主动询问kernel数据好了没有
但是在fd少的情况下还可以,要是多了起来,有1000个fd,那么用户进程就要轮循1000次,会有一定的成本
老李去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。
耗费:往返车站6次,路上6小时,其他时间做了好多事。
I/O 多路复用( IO multiplexing)
IO multiplexing就是我们说的select、poll、epoll。select/epoll的好处就在于单个进程就可以同时处理多个网络连接的IO。
select-poll: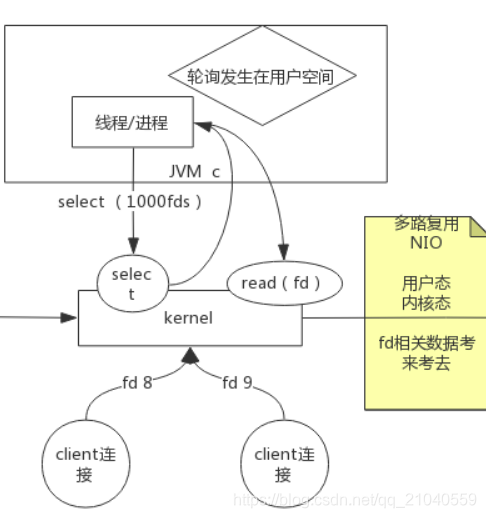
原来是写个死循环去轮循,现在不写死循环了,我们直接把1000个fd传给内核,内核去轮循监听然后返回fd,返回的fd会被标识有无数据,这个时候再去调用read去读取有数据的fd
缺点:
- 有1024个socket数组个数的限制
- 需要遍历轮询触发找到真正有信号的 socket连接
老李去火车站买票,委托黄牛,然后每隔6小时电话黄牛询问,黄牛三天内买到票,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,黄牛手续费100元,打电话17次
epoll:
上面select/poll还是有点复杂,fd相关的数据会被拷来拷去。于是出现epoll
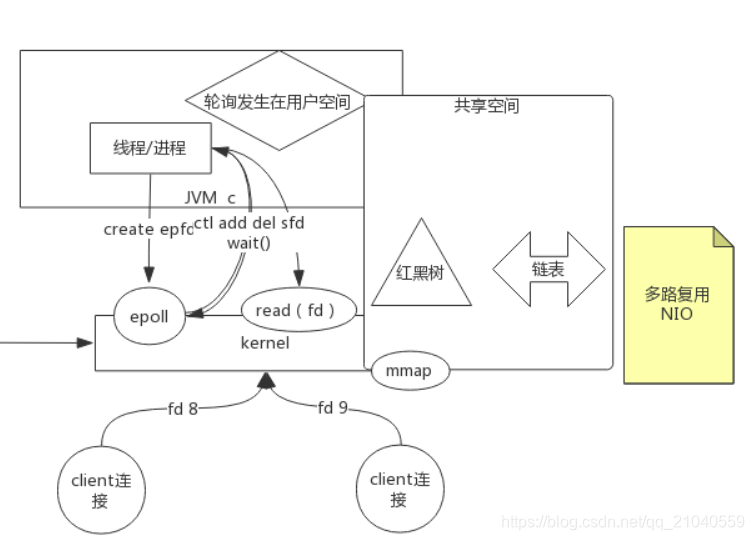
共享空间是通过mmap系统调用来实现的。
工作过程:
1000个fd直接放入共享空间的红黑树,然后内核可以看到共享空间的数据,然后内核就通过IO、中断找出那个fd的数据到达了等。然后把到达的放入到链表中。然后通过回调函数用户空间就可以直接从链表中拿取fd去read。这样就省略了fd拷贝的过程。
相较于select/poll的改进:
- 没有1024数组个数的限制
- 去掉了遍历文件描述符,而是使用监听回调的的机制
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,免黄牛费100元,无需打电话
异步 I/O(AIO)
inux下的asynchronous IO其实用得很少。大概流程就是:
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李并快递送票上门。
耗费:往返车站1次,路上1小时,免黄牛费100元,无需打电话
区别
1同2的区别是:自己轮询
2同3的区别是:委托黄牛
3同4的区别是:电话代替黄牛
4同5的区别是:电话通知是自取还是送票上门
select、poll、epoll的区别
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。 但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。



