深入剖析核心ByteBuf缓冲区
工作原理
Java NIO 提供了ByteBuffer 作为它 的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。Netty 的 ByteBuffer 替代品是 ByteBuf。
从结构上来说,ByteBuf 由一串字节数组构成。数组中每个字节用来存放信息。ByteBuf 提供了两个索引,一个用于读取数据,一个用于写入数据。这两个索引通过在字节数组中移动,来定位需要读或者写信息的位置。
当从 ByteBuf 读取时,它的 readerIndex(读索引)将会根据读取的字节数递增。
同样,当写 ByteBuf 时,它的writerIndex(写索引) 也会根据写入的字节数进行递增。
ByteBuf内部空间结构:
discardable bytes – 可丢弃的字节空间(已经读过的块儿)
readable bytes – 可读的字节空间
writable bytes --可写的字节空间
capacity bytes – 最大的可容量空间
如果 readerIndex 超过了 writerIndex 的时候,Netty 会抛出 IndexOutOf-BoundsException 异常。
索引指针详解
ByteBuf的三个指针:
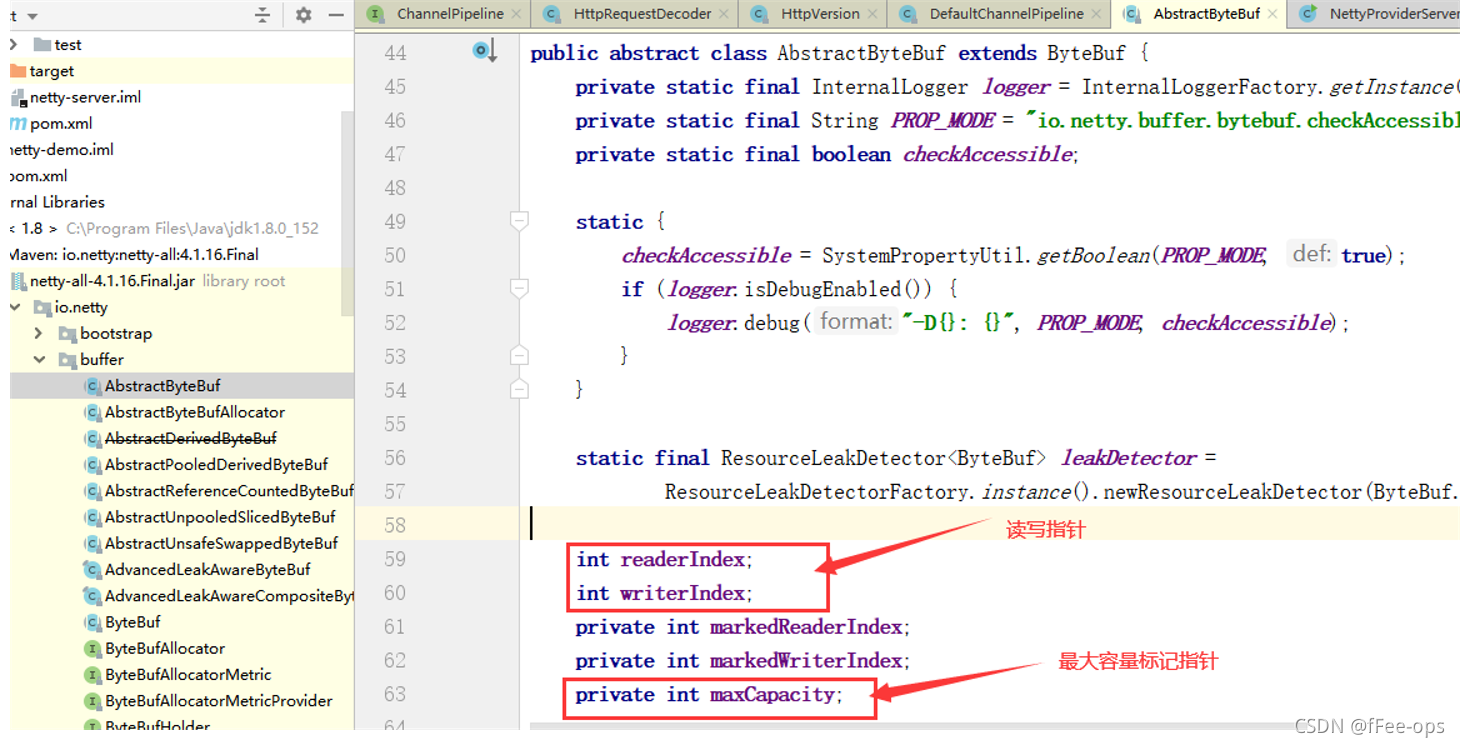
- readerIndex(读指针)
指示读取的起始位置, 每读取一个字节, readerIndex自增累加1。 如果readerIndex 与writerIndex 相等,ByteBuf 不可读 。 - writerIndex(写指针)
指示写入的起始位置, 每写入一个字节, writeIndex自增累加1。如果增加到 writerIndex 与capacity() 容量相等,表示 ByteBuf 已经不可写。 - maxCapacity(最大容量)
指示ByteBuf 可以扩容的最大容量, 如果向ByteBuf写入数据时, 容量不足, 可以进行扩容。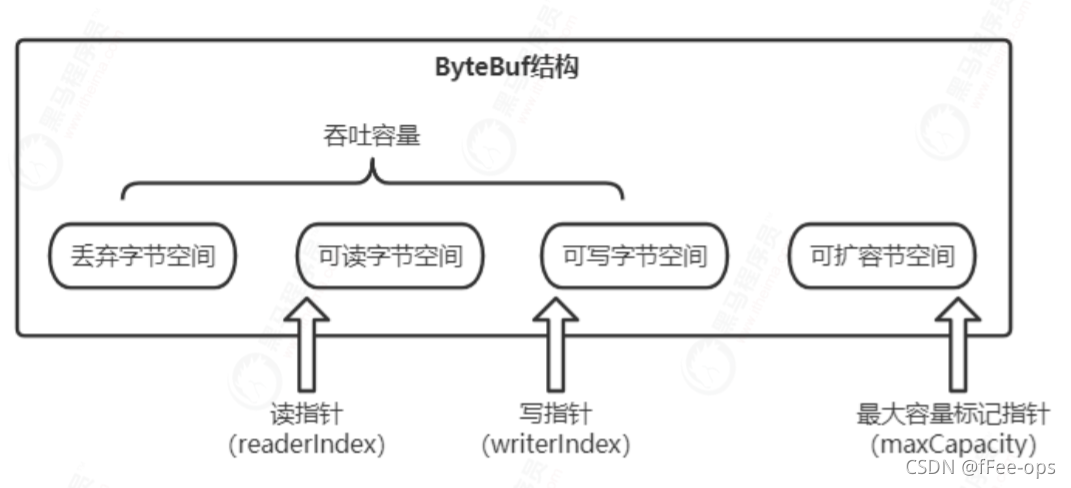
源码:io.netty.buffer.AbstractByteBuf
缓冲区的使用
读取操作
package netty.bytebuf;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.util.CharsetUtil;
/**
* Created by yazai
* Date: 23:28 2021/10/30
* Description:
*/
public class TestRead {
public static void main(String[] args) {
//构造
ByteBuf byteBuf = Unpooled.copiedBuffer("hello world",
CharsetUtil.UTF_8);
System.out.println("byteBuf的容量为:" + byteBuf.capacity());
System.out.println("byteBuf的可读容量为:" + byteBuf.readableBytes());
System.out.println("byteBuf的可写容量为:" + byteBuf.writableBytes());
while (byteBuf.isReadable()) { //方法一:内部通过移动readerIndex进行读取
System.out.println((char) byteBuf.readByte());
}
//方法二:通过下标直接读取
for (int i = 0; i < byteBuf.readableBytes(); i++) {
System.out.println((char) byteBuf.getByte(i));
}
//方法三:转化为byte[]进行读取
byte[] bytes = byteBuf.array();
for (byte b : bytes) {
System.out.println((char) b);
}
}
}

写入操作
package netty.bytebuf;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
/**
* Created by yazai
* Date: 23:31 2021/10/30
* Description:
*/
public class testwrite {
public static void main(String[] args) {
//构造空的字节缓冲区,初始大小为10,最大为20
ByteBuf byteBuf = Unpooled.buffer(10, 20);
System.out.println("byteBuf的容量为:" + byteBuf.capacity());
System.out.println("byteBuf的可读容量为:" + byteBuf.readableBytes());
System.out.println("byteBuf的可写容量为:" + byteBuf.writableBytes());
for (int i = 0; i < 5; i++) {
byteBuf.writeInt(i); //写入int类型,一个int占4个字节
}
System.out.println("ok");
System.out.println("byteBuf的容量为:" + byteBuf.capacity());
System.out.println("byteBuf的可读容量为:" + byteBuf.readableBytes());
System.out.println("byteBuf的可写容量为:" + byteBuf.writableBytes());
while (byteBuf.isReadable()) {
System.out.println(byteBuf.readInt());
}
}
}

丢弃处理
通过discardReadBytes()方可以将已经读取的数据进行丢弃处理,就可以回收已经读取的字节空间
package netty.bytebuf;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.util.CharsetUtil;
/**
* Created by yazai
* Date: 23:35 2021/10/30
* Description:测试丢弃功能
*/
public class TestThrow {
public static void main(String[] args) {
ByteBuf byteBuf = Unpooled.copiedBuffer("hello world",
CharsetUtil.UTF_8);
System.out.println("byteBuf的容量为:" + byteBuf.capacity());
System.out.println("byteBuf的可读容量为:" + byteBuf.readableBytes());
System.out.println("byteBuf的可写容量为:" + byteBuf.writableBytes());
while (byteBuf.isReadable()) {
System.out.println((char) byteBuf.readByte());
}
byteBuf.discardReadBytes(); //丢弃已读的字节空间
System.out.println("byteBuf的容量为:" + byteBuf.capacity());
System.out.println("byteBuf的可读容量为:" + byteBuf.readableBytes());
System.out.println("byteBuf的可写容量为:" + byteBuf.writableBytes());
}
}

清理功能
通过clear() 重置readerIndex 、 writerIndex 为0,需要注意的是,重置并没有删除真正的内容。
那么为什么没有真正删除其中的内容?
调用clear方法后, 如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先写入一些数据,那么使用
compact()。compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。Buffer准备好新的写入数据了,并且不会覆盖未读的数据。
缓冲区使用模式
根据存放缓冲区的不同分为三类:
- 堆缓冲区(HeapByteBuf),内存的分配和回收速度比较快,可以被JVM自动回收,缺点是,如果进行socket的IO读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核Channel中,性能会有一定程度的下降。由于在堆上被 JVM 管理,在不被使用时可以快速释放。可以通过ByteBuf.array() 来获取 byte[] 数据。
- 直接缓冲区(DirectByteBuf),非堆内存,它在堆外进行内存分配,相比堆内存,它的分配和回收速度会慢一些,但是将它写入或从Socket Channel中读取时,由于减少了一次内存拷贝,速度比堆内存块。
- 复合缓冲区,顾名思义就是将上述两类缓冲区聚合在一起。Netty 提供了一个CompsiteByteBuf,可以将堆缓冲区和直接缓冲区的数据放在一起,让使用更加方便。
ByteBuf 的分配
//通过ChannelHandlerContext获取ByteBufAllocator实例
ctx.alloc();
//通过channel也可以获取
channel.alloc();
Netty 提供了两种 ByteBufAllocator 的实现,分别是:
- PooledByteBufAllocator,实现了 ByteBuf 的对象的池化,提高性能减少并最大限度地减少内存碎片。
- UnpooledByteBufAllocator,没有实现对象的池化,每次会生成新的对象实例。
//Netty默认使用了PooledByteBufAllocator
//可以在引导类中设置非池化模式
serverBootstrap.childOption(ChannelOption.ALLOCATOR,
UnpooledByteBufAllocator.DEFAULT);
//或通过系统参数设置
System.setProperty("io.netty.allocator.type", "pooled");
System.setProperty("io.netty.allocator.type", "unpooled");
ByteBuf的释放
ByteBuf如果采用的是堆缓冲区模式的话,可以由GC回收,但是如果采用的是直接缓冲区,就不受GC的管理,就得手动释放,否则会发生内存泄露。关于ByteBuf的释放,分为手动释放与自动释放。
手动释放
手动释放,就是在使用完成后,调用ReferenceCountUtil.release(byteBuf); 进行释放。通过release方法减去 byteBuf 的使用计数,Netty 会自动回收 byteBuf 。手动释放可以达到目的,但是这种方式会比较繁琐,如果一旦忘记释放就可能会造成内存泄露。
/**
* 获取客户端发来的数据
*
* @param ctx
* @param msg
* @throws Exception
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws
Exception {
ByteBuf byteBuf = (ByteBuf) msg;
String msgStr = byteBuf.toString(CharsetUtil.UTF_8);
System.out.println("客户端发来数据:" + msgStr);
//释放资源
ReferenceCountUtil.release(byteBuf);
}
自动释放:
自动释放有三种方式,分别是:入站的TailHandler、继承SimpleChannelInboundHandler、HeadHandler的出站释放。
TailHandler:
Netty的ChannelPipleline的流水线的最后一个Handler是TailHandler,默认情况下如果每个入站处理器Handler都把消息往下传,TailHandler会释放掉ReferenceCounted类型的消息。
需要注意的是,如果没有进行向下传递,那么在TailHandler中是不会进行释放操作的。
/**
* 获取客户端发来的数据
*
* @param ctx
* @param msg
* @throws Exception
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws
Exception {
ByteBuf byteBuf = (ByteBuf) msg;
String msgStr = byteBuf.toString(CharsetUtil.UTF_8);
System.out.println("客户端发来数据:" + msgStr);
//向客户端发送数据
ctx.writeAndFlush(Unpooled.copiedBuffer("ok", CharsetUtil.UTF_8));
ctx.fireChannelRead(msg); //将ByteBuf向下传递,即数据下沉
}
源码:
在io.netty.channel.DefaultChannelPipeline中的TailContext内部类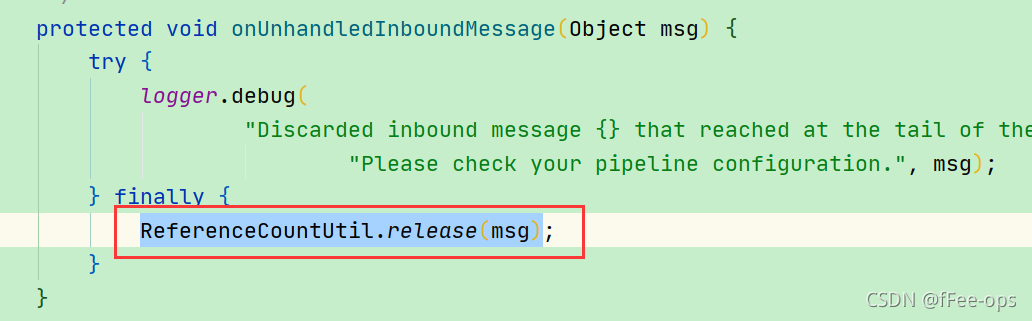
SimpleChannelInboundHandler:
当ChannelHandler继承了SimpleChannelInboundHandler后,在SimpleChannelInboundHandler的channelRead()方法中,将会进行资源的释放,我们的业务代码也需要写入到channelRead0()中。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.SimpleChannelInboundHandler;
import io.netty.util.CharsetUtil;
public class MyClientHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
protected void channelRead(ChannelHandlerContext ctx, ByteBuf msg)
throws Exception {
System.out.println("接收到服务端的消息:" +
msg.toString(CharsetUtil.UTF_8));
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// 向服务端发送数据
String msg = "hello";
ctx.writeAndFlush(Unpooled.copiedBuffer(msg, CharsetUtil.UTF_8));
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
cause.printStackTrace();
ctx.close();
}
}
HeadHandler
出站处理流程中,申请分配到的 ByteBuf,通过 HeadHandler 完成自动释放。出站处理用到的 Bytebuf 缓冲区,一般是要发送的消息,通常由应用所申请。在出站流程开始的时候,通过调用ctx.writeAndFlush(msg),Bytebuf 缓冲区开始进入出站处理的 pipeline 流水线。
在每一个出站Handler中的处理完成后,最后消息会来到出站的最后一棒 HeadHandler,再经过一轮复杂的调用,在flush完成后终将被release掉。
public class MyClientHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg)
throws Exception {
System.out.println("接收到服务端的消息:" +
msg.toString(CharsetUtil.UTF_8));
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// 向服务端发送数据
String msg = "hello";
ctx.writeAndFlush(Unpooled.copiedBuffer(msg, CharsetUtil.UTF_8));
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
cause.printStackTrace();
ctx.close();
}
}
小结
- 入站处理流程中,如果对原消息不做处理,调用 ctx.fireChannelRead(msg) 把原消息往下传,由流水线最后一棒 TailHandler 完成自动释放。
- 如果截断了入站处理流水线,则可以继承 SimpleChannelInboundHandler ,完成入站ByteBuf自动释放。
- 出站处理过程中,申请分配到的 ByteBuf,通过 HeadHandler 完成自动释放。
- 入站处理中,如果将原消息转化为新的消息并调用 ctx.fireChannelRead(newMsg)往下传,那必须把原消息release掉;
- 入站处理中,如果已经不再调用 ctx.fireChannelRead(msg) 传递任何消息,也没有继承SimpleChannelInboundHandler 完成自动释放,那更要把原消息release掉;



