@toc
1、负载均衡怎么做的?
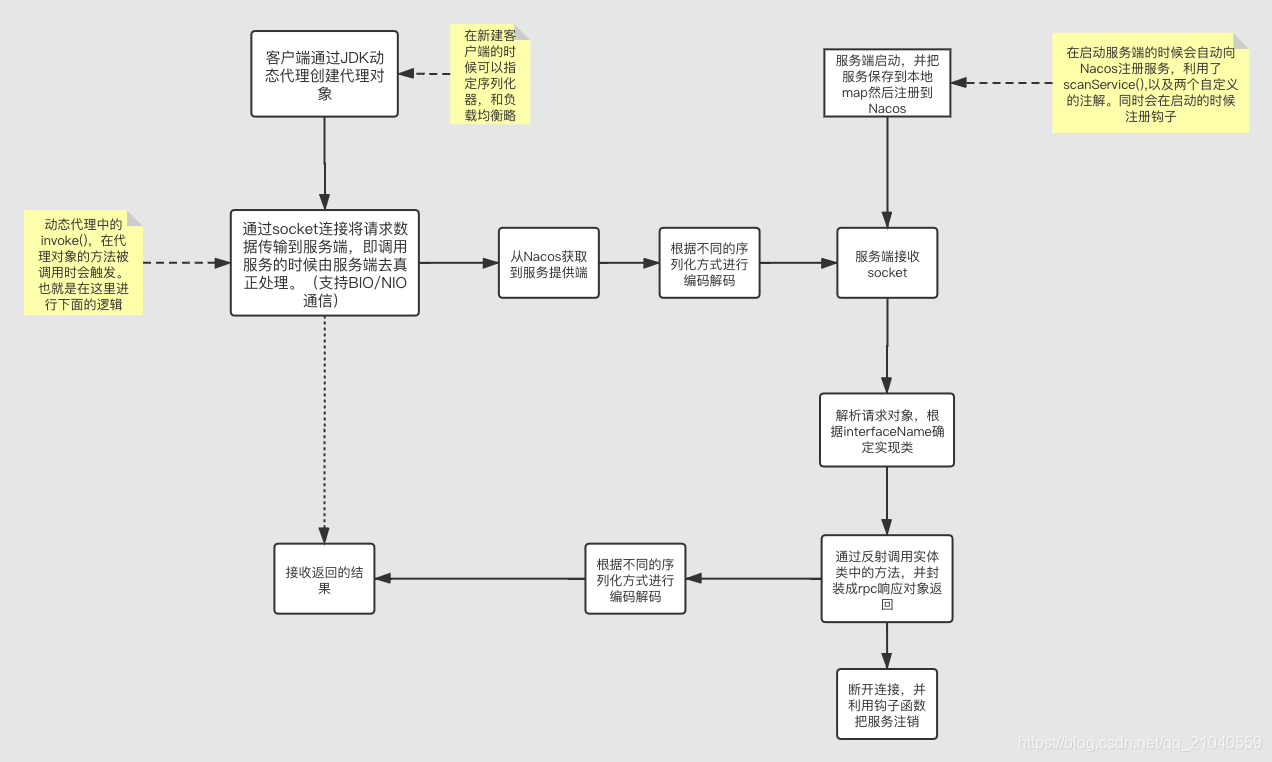
我们可以从Nacos中获得所有提供这个服务的列表,要从中选择一个,那就涉及到客户端侧的负载均衡,所以只要创建一个负载均衡的接口,再去实现它就行了,目前就实现了随机、轮询两种,在创建客户端的时候可以指定,如果不指定默认是随机
2、网络模块怎么做的?
可以选择BIO和NIO
3、操作系统的内核态缓冲区存储什么数据呢?
存放的用户进程要读取或者写入的数据
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。
4、Java哪些操作涉及到了系统调用呢?
5、JDK原生序列化和JSON序列化的区别,为什么原生序列化效率低?
java原生序列化:
1. 它必须要实现serializable接口。它会将对象转为字节序列,可以重建对象。
2. 是通过对象输出流(ObjectOutputStream)和输入流(ObjectInputStream)来保存和重构对象。
json序列化:
其实就是把数据转化成一种字符串
区别:
- serialize在编码后大概是json的两倍
serialize后字符串包含了子串的长度,这可能是速度方面的优化,典型的空间换时间,但是它本身还是太重了。
serialize有更加详细的类型区分,而json类型比较少,并且是以简单的符号表示。 - serialize的速度在大数据量的情况下比json差了快一个数量级。
效率低的原因:
由于Java序列化采用同步阻塞IO,相对于目前主流的序列化协议,它的效率非常差。
6、Kryo序列化了解吗?
它旨在提供快速、高效和易用的 API,可以执行自动深拷贝、浅拷贝。这是对象到对象的直接拷贝,而不是对象->字节->对象的拷贝。
区别:
kryo 速度较快,序列化后体积较小,但是跨语言支持较复杂。
7、服务注册说说?
在服务端启动的时候,会自动向Nacos注册服务,它会先把服务保存到一个本地列表,然后再去向Nacos注册。这个自动注册就用到了两个自定义的注解,一个是@service一个是@ServiceScan。
@Service 放在一个类上,标识这个类提供一个服务,@ServiceScan 放在启动的入口类上,标识扫描的包的范围。Service 注解的值定义为该服务的名称,默认值是该类的完整类名。ServiceScan 的值定义为扫描范围的根包,默认值为入口类所在的包。扫描的时候会扫描时会扫描该包及其子包下所有的类,找到标记有 Service 的类,并注册。
自动注册的流程
- 获得要扫描的包的范围,就需要获取到 ServiceScan 注解的值
- 然后获取到所有的 Class
- 逐个判断是否有 @Service 注解,如果有的话,通过反射获得该对象,并且调用 publishService 注册即可
8、Nacos存储的数据是怎么映射的?
在注册服务时,默认采用这个对象实现的接口的完整类名作为服务名,然后提供服务者的ip地址和端口,根据这个来注册到Nacos。
这种处理方式也就说明了某个接口只能有一个对象提供服务。
9、序列化遇到的坑
背景:使用的是json序列化:
在 RpcRequest 反序列化时,由于其中有一个字段是 Object 数组,在反序列化时序列化器会根据字段类型进行反序列化,而 Object 就是一个十分模糊的类型,会出现反序列化失败的现象,这时就需要 RpcRequest 中的另一个字段 ParamTypes来获取到 Object 数组中的每个实例的实际类,辅助反序列化
10、自定义协议/数据格式?
+---------------+---------------+-----------------+-------------+
| Magic Number | Package Type | Serializer Type | Data Length |
| 4 bytes | 4 bytes | 4 bytes | 4 bytes |
+---------------+---------------+-----------------+-------------+
| Data Bytes |
| Length: ${Data Length} |
+---------------------------------------------------------------+
Magic Number:标识这是我的协议包
Package Type:标明这是一个调用请求还是调用相应
Serializer Type:标明使用的序列化器,这个客户端和服务端应当保持一致
Data Length:实际数据的长度,设置这个字段主要防止粘包
Data Bytes:经过序列化后的实际数据
11、自定义注解怎么做的?
要自己定义一个自定义注解,就要用到@target:Target注解决定自定义注解可以加在哪些成分上,如加在类身上,或者属性身上,或者方法身上等成分
@Retention:Retention注解决定自定义注解的生命周期,比如我就是用的@Retention(RetentionPolicy.RUNTIME):这个注解的生命周期一直程序运行时都存在
12、request里面有什么属性?

13、粘包问题怎么解决的?
我们自定义了包头部的数据为4个字节,我们每次先读到这4个字节,然后再拿到实习的数据长度,去读取
14、Netty的epoll模型相较于原来的做了什么改变?
把边缘触发改成了水平触发
15、边缘触发为什么比水平触发效率高?
水平触发是只要读缓冲区有数据,就会一直触发可读信号,而边缘触发仅仅在空变为非空的时候通知一次。
边缘模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高



