1. 发展历程
https://kafka.apache.org/downloads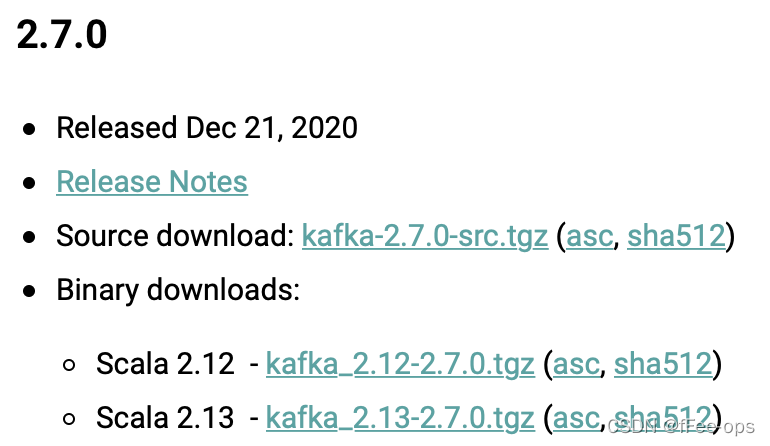
1.1 版本命名
Kafka在1.0.0版本前的命名规则是4位,比如0.8.2.1,0.8是大版本号,2是小版本号,1表示打过1个补丁。
现在的版本号命名规则是3位,格式是“大版本号”+“小版本号”+“修订补丁数”,比如2.5.0,前面的2代表的是大版本号,中间的5代表的是小版本号,0表示没有打过补丁。
我们所看到的下载包,前面是scala编译器的版本,后面才是真正的kafka版本。比如
1.2 演进历史
0.7版本 只提供了最基础的消息队列功能。
0.8版本 引入了副本机制,至此Kafka成为了一个真正意义上完备的分布式高可靠消息队列解决方案。
0.9版本 增加权限和认证,使用Java重写了新的consumer API,Kafka Connect功能;不建议使用consumer API;
0.10版本 引入Kafka Streams功能,正式升级成分布式流处理平台;建议版本0.10.2.2;建议使用新版consumer API
0.11版本 producer API幂等,事务API,消息格式重构;建议版本0.11.0.3;谨慎对待消息格式变化
1.0和2.0版本 Kafka Streams改进;建议版本2.0;
2. 单机安装
前提是zookeeper已经安装并启动了。
本次安装kafka的版本为2.8.0
2.1 下载 kafka
地址: http://kafka.apache.org/downloads.html
Source download: kafka-2.5.0-src.tgz (asc, sha512) # 此为源代码, 需要自己编译
Binary downloads:
Scala 2.12 - kafka_2.12-2.5.0.tgz (asc, sha512) # 已编译好的, 前面的2.12为 Scala版本
Scala 2.13 - kafka_2.13-2.5.0.tgz (asc, sha512)
2.2 解压安装包
tar -zxvf kafka_2.13-2.5.0.tgz
2.3 修改配置文件
进入到kafka的config目录下
vim server.properties
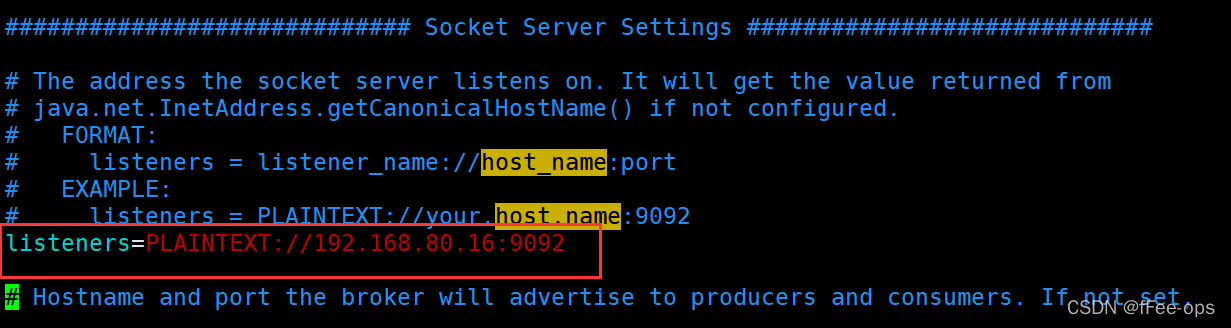
其实主要就修改zookeeper的链接配置,和启用监听器。其余都不用动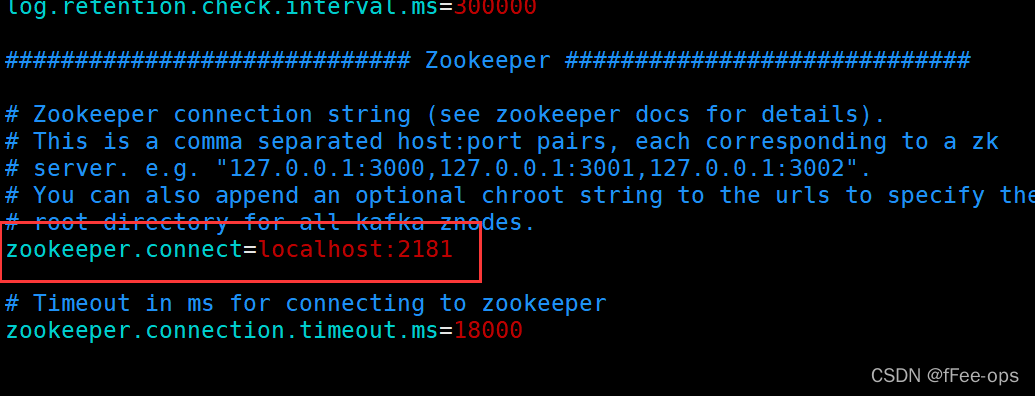
2.4 启动 kafka
在kafka根目录下执行以下命令来后台运行kafka
nohup ./bin/kafka-server-start.sh config/server.properties &
如果启动的时候出现错误: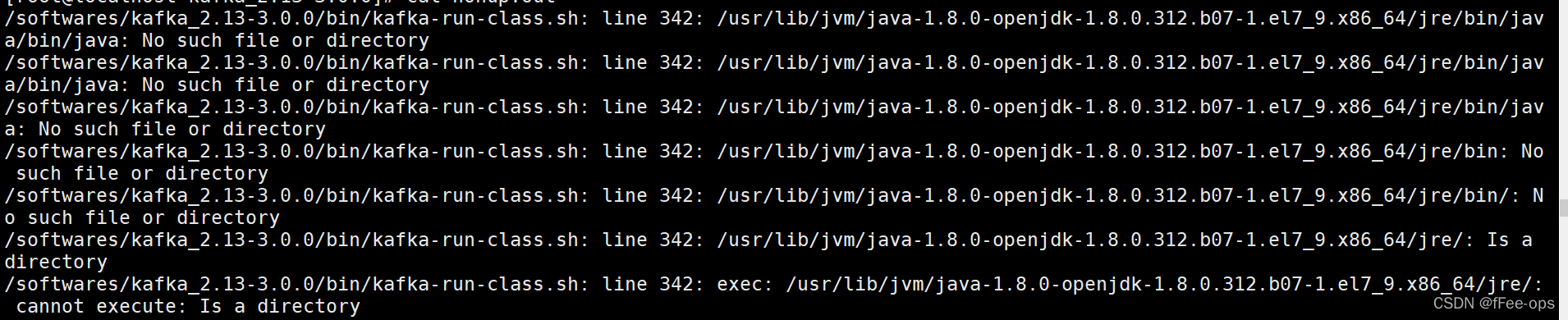
也就是找不到你的jdk。
这个时候去修改bin/kafka-run-class.sh。
vim ./bin/kafka-run-class.sh
搜索JAVA_HOME,并且将红色框内容替换为JDK的绝对路径。
2.5 验证
使用jps命令可以看到是否启动成功:
3. 组件使用
3.1 创建 topic
2.x版本
在kafka根目录下执行:
# 创建 1个分区 1个副本的 topic
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hello

3.x版本
在kafka根目录下执行:
# 创建 1个分区 1个副本的 topic
./bin/kafka-topics.sh --create --bootstrap-server 192.168.80.16:9092 --replication-factor 1 --partitions 1 --topic testTopic(主题名称)

注意的点:--bootstrap-server后不能使用localhost,必须填写ip
而且还需要注意:
对于版本 2.*,您必须使用 Zookeper 创建主题,并使用默认端口 2181 作为参数。
对于版本 3.*,zookeeper 不再是参数,您应该使用 --bootstrap-server 使用 localhost 或服务器的 IP 地址和默认端口 9092
3.2 查看 topic
./bin/kafka-topics.sh --list --zookeeper localhost:2181

3.3 发送消息
发送消息默认使用的是 9092 端口, kafka 链接 zookeeper 默认端口是 2181 这两个是不一样的, 要注意.
./bin/kafka-console-producer.sh --broker-list 192.168.80.16:9092 --topic hello
不能用localhost

3.4 消费消息
复制一个新的窗口进行消息消费。
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.80.16:9092 --topic hello
不能用localhost
此时在发送端进行发送,再来看接收端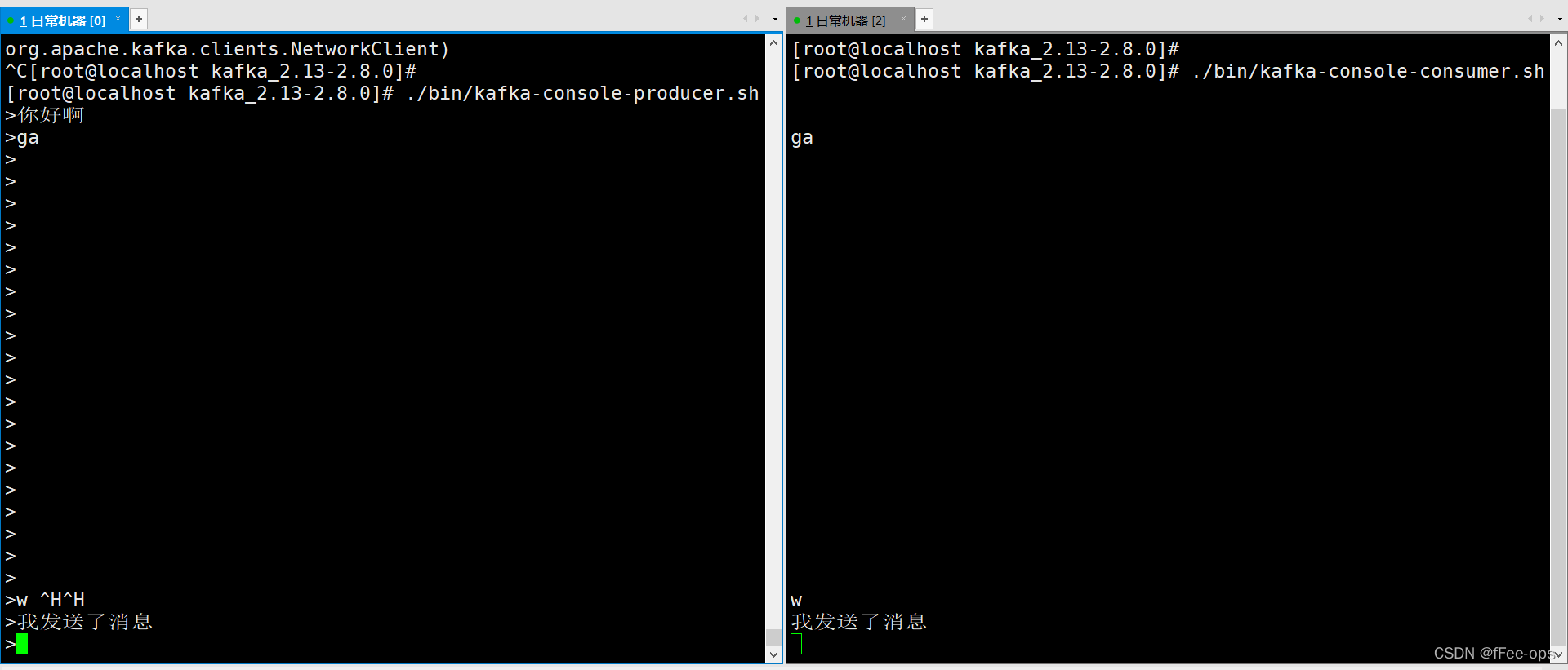
3.5 删除 topic
./bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic hello

再来看看topic列表发现hello已经被删除了
3.6 主题详情
./bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic testTopic

3.7 分组消费
启动两个consumer时,如果不指定group信息,消息被广播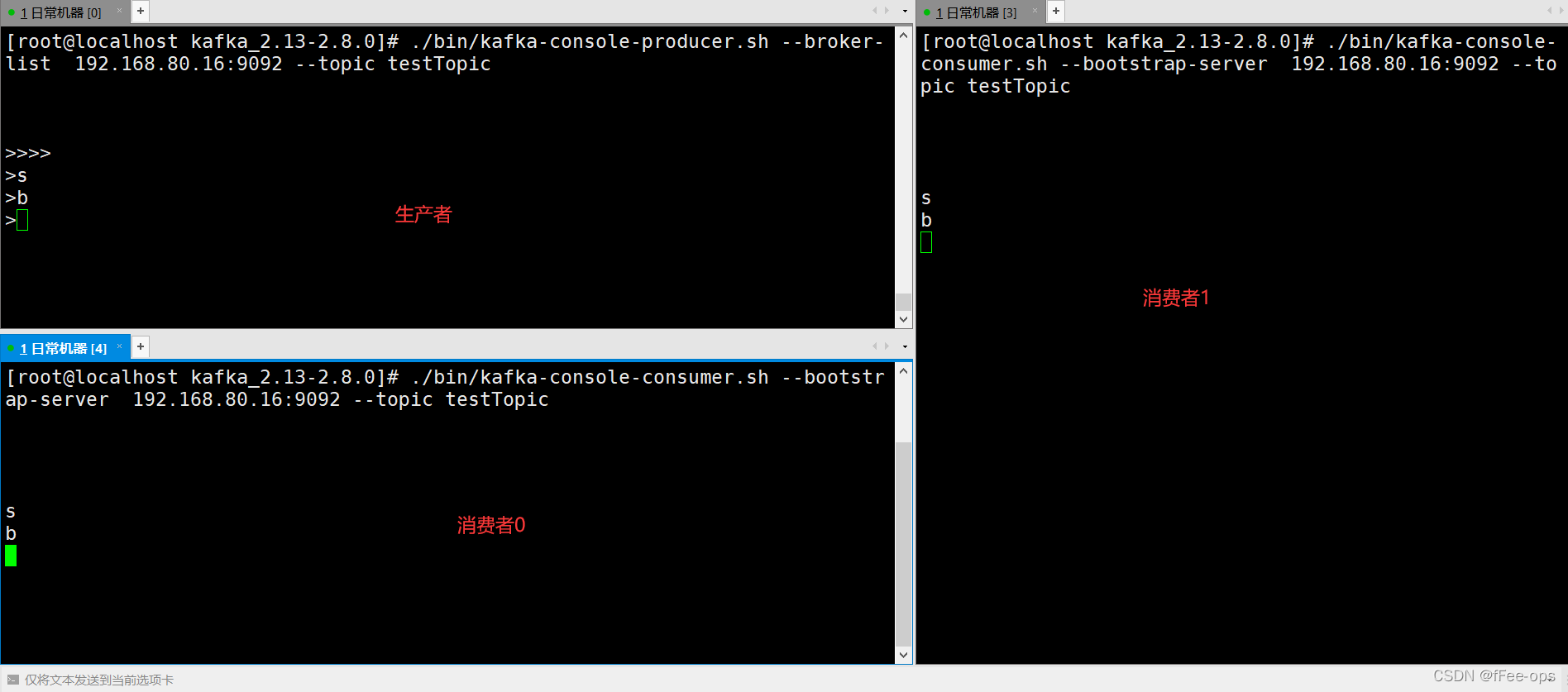
指定相同的group,发现只有一个消费者可以获得消息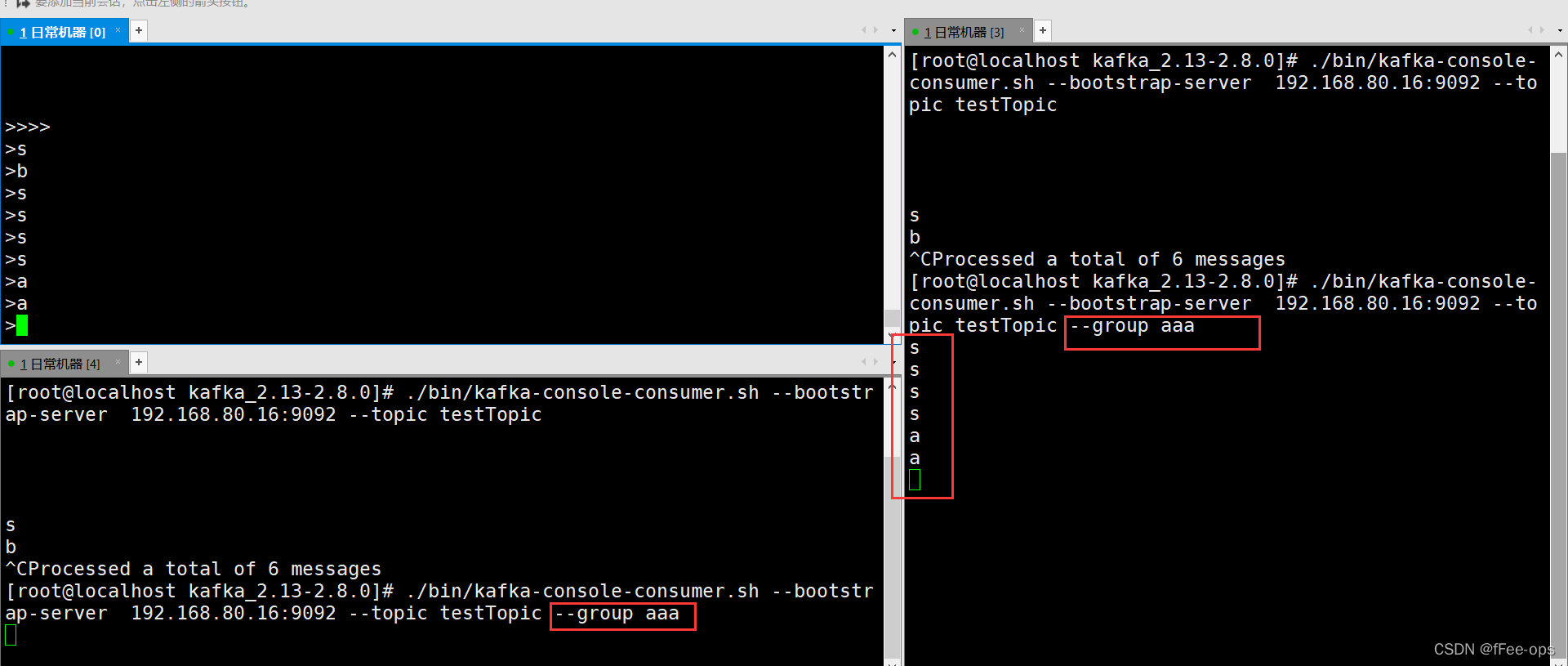
注意,此时的testTopic的分区数为:1个,所以同一group的2个消费者会有一个闲置。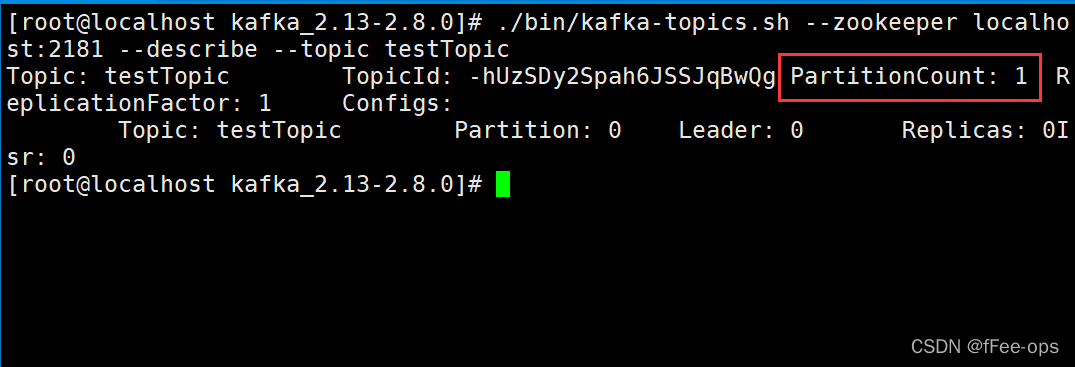
新创建一个主题hi,分区为2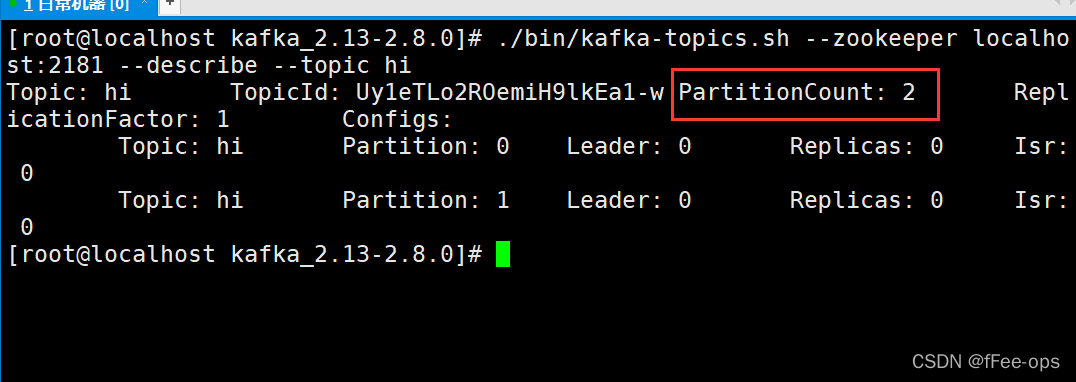
此时可以看到两个消费者是交替进行消费的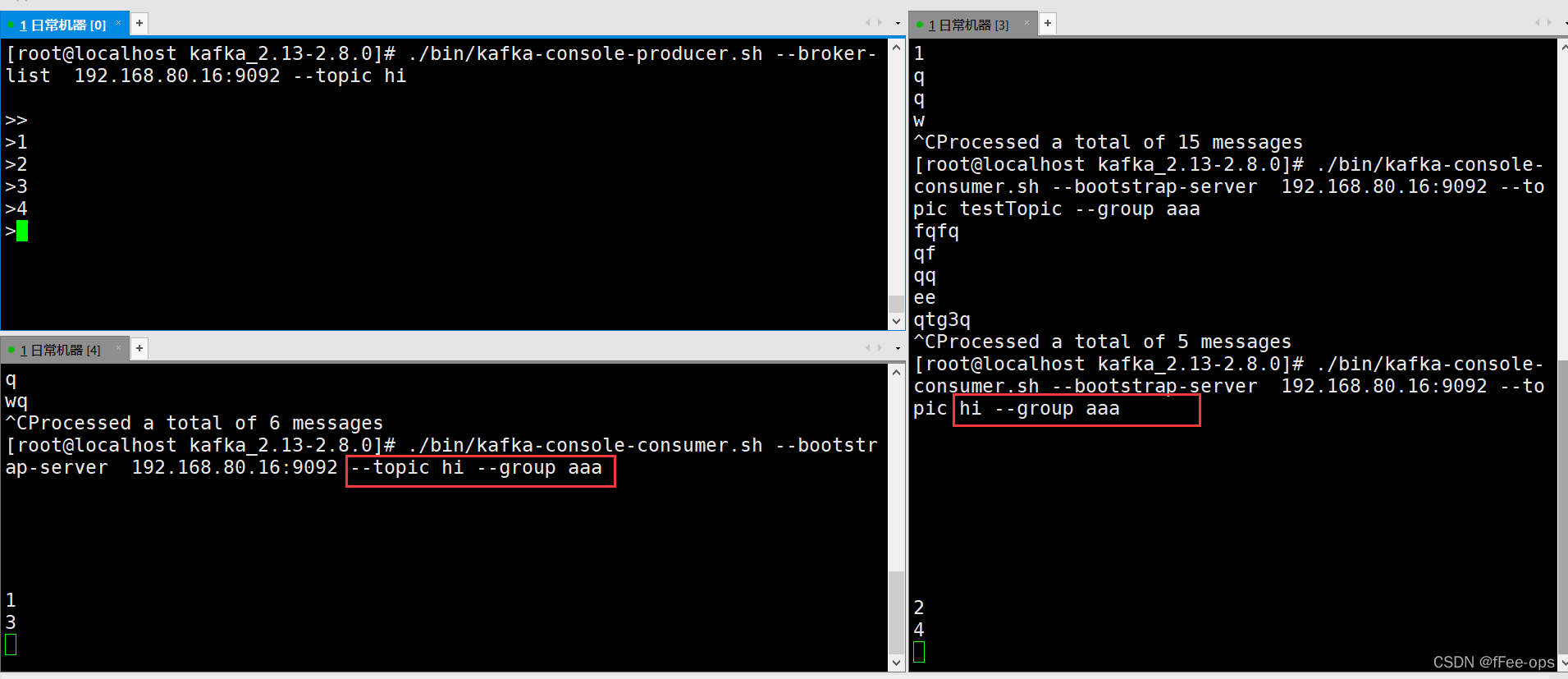
总结:如果同一group下的 ( 消费者数量 > 分区数量 ) 那么就会有消费者闲置。
3.8 指定分区
指定消费者消费分区通过参数 --partition,注意!需要去掉group。
指定分区的意义在于,保障消息传输的顺序性。
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.80.16:9092 --topic hi --partition 0
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.80.16:9092 --topic hi --partition 1
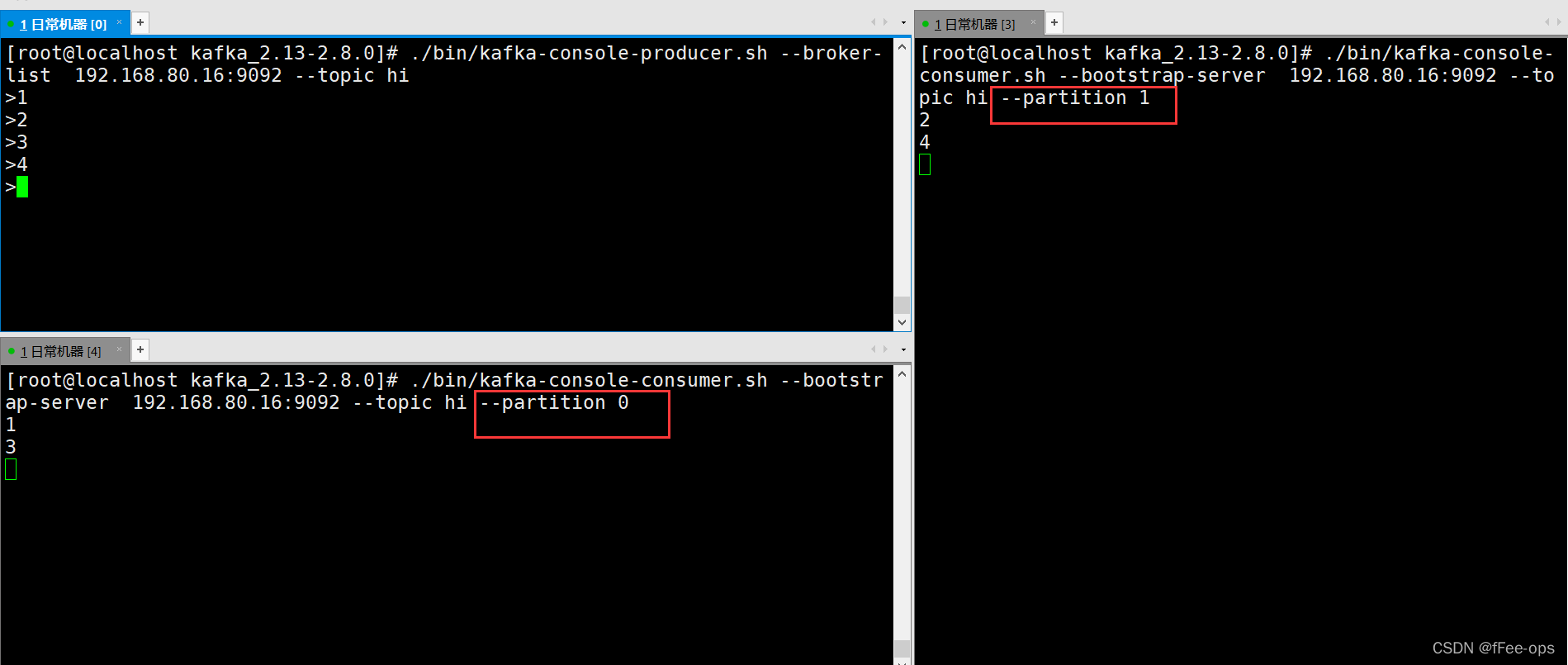
发送1-4条消息,交替出现。说明消息被均分到各个分区中投递
默认的发送是没有指定key的,要指定分区发送,就需要定义key。那么相同的key被路由到同一个分区。
./bin/kafka-console-producer.sh --broker-list 192.168.80.16:9092 --topic hi --property parese.key=true
携带key再发送,注意key和value之间用tab分割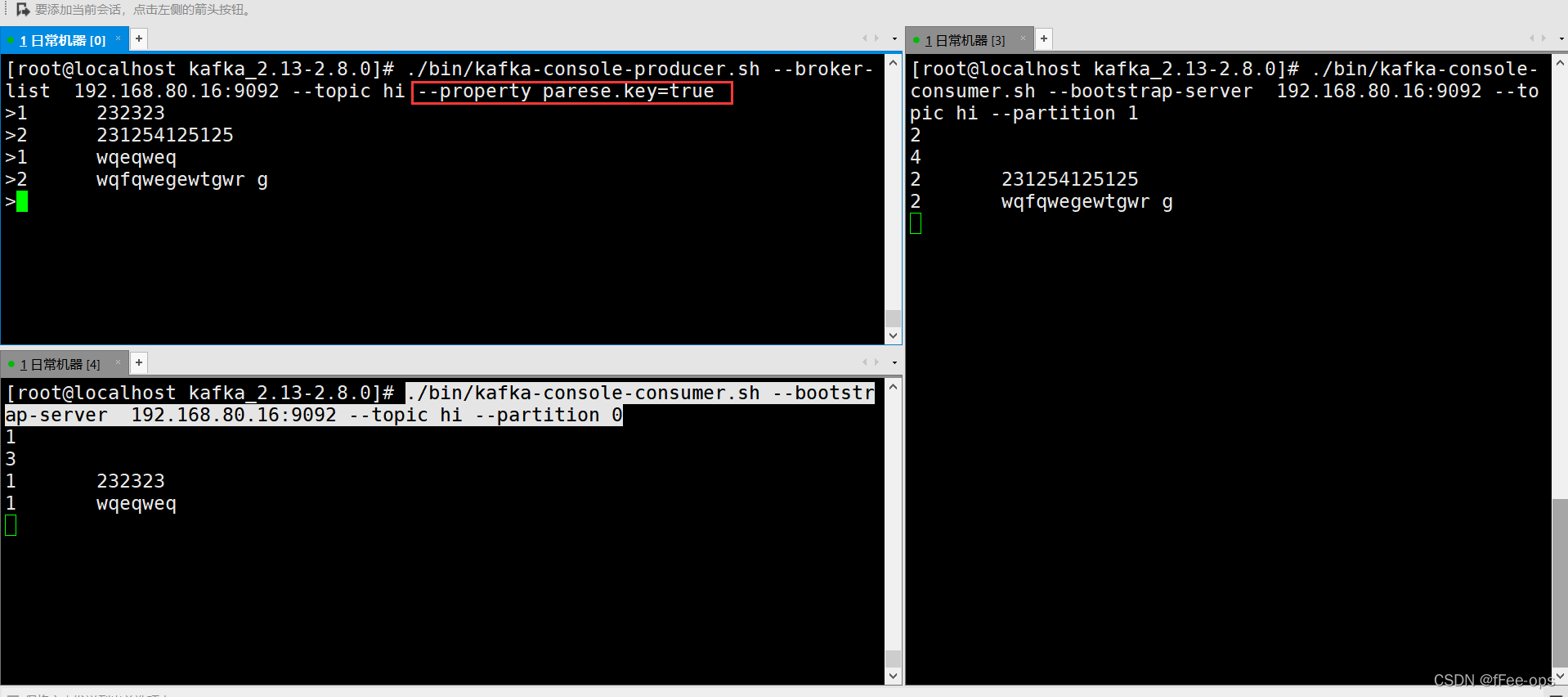
结果:相同的key被同一个consumer消费掉
3.9 偏移量
偏移量决定了消息从哪开始消费,支持:开头,还是末尾。
- earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
- latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
- none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.80.16:9092 --topic hi --partition 0 --offset earliest
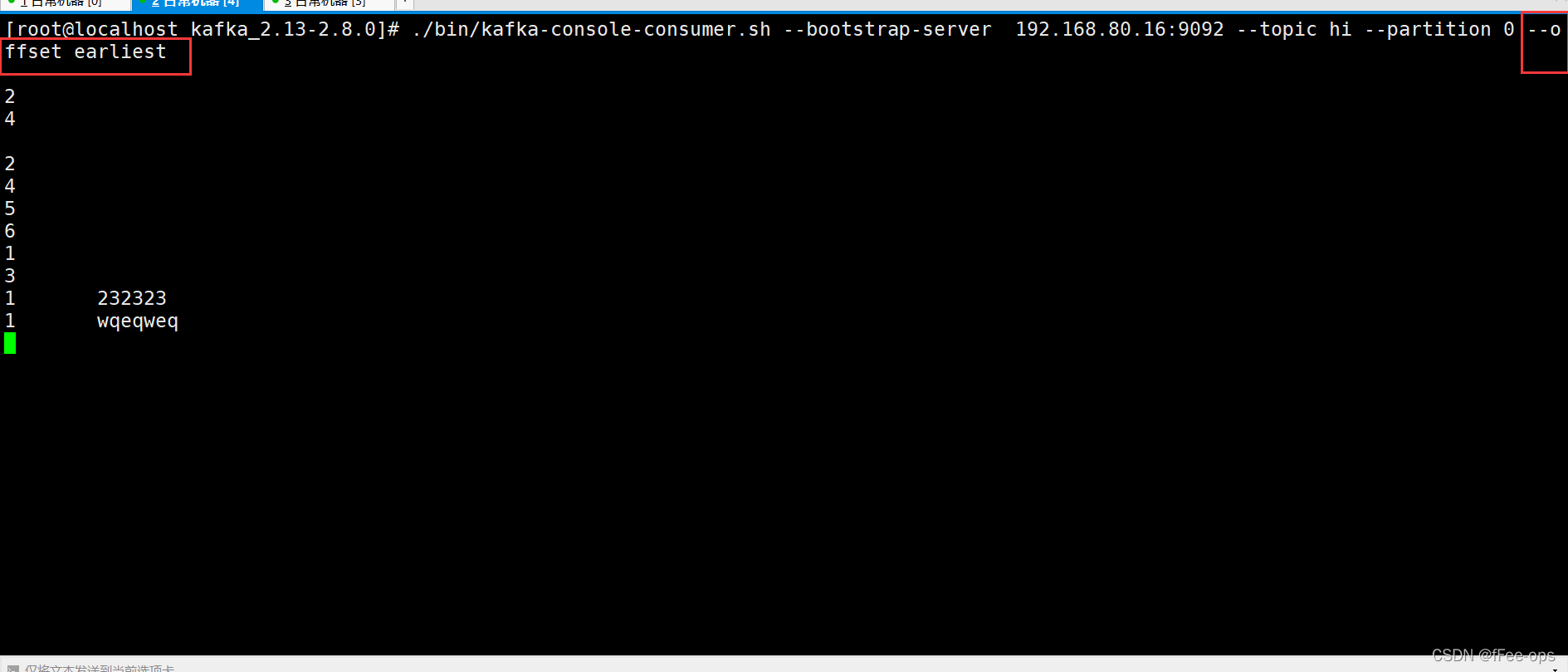
结果:之前发送的消息,从头又消费了一遍
4. zookeeper分析
zk存储了kafka集群的相关信息,本节来探索内部的秘密。
在zk客户端输入命令
ls /

得到以下配置信息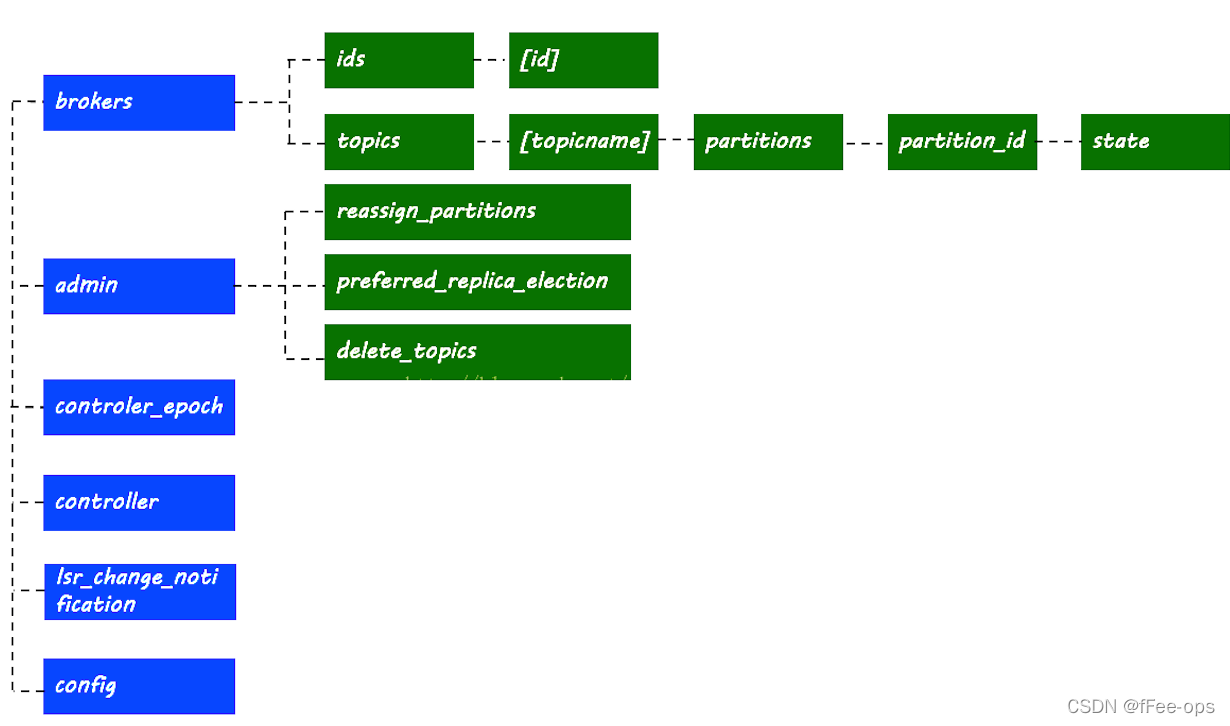
4.1 broker信息



4.2 主题与分区
分区节点路径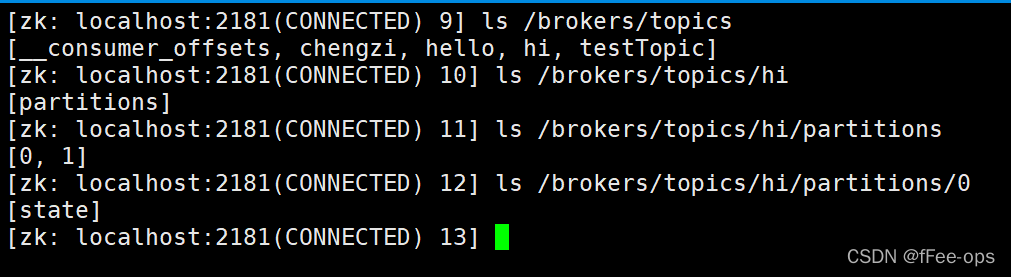
分区信息,leader所在的机器id,isr列表等
4.3 消费者与偏移量

居然是空的??原来现在kafka已经自身去维护 group 的消费 偏移量了。
查看方式:
上面的消费用的是控制台工具,这个工具使用–bootstrap-server,不经过zk,也就不会记录到/consumers下。
其消费者的offset会更新到一个kafka自带的topic【__consumer_offsets】下面。
消费消息后,查看TOPIC可以发现多了一个__consumer_offsets
我们之前用过一个group:aaa
输入命令查看消费者及偏移量情况:
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.80.16:9092 --list

查看偏移量详情:
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.80.16:9092 --describe --group aaa

如果当前与LEO保持一致,说明消息都完整的被消费过:
停掉consumer后,往provider中再发几条记录,offset开始滞后:
重新启动consumer,消费到最新的消息,同时再返回看偏移量,消息得到同步:
4.4 controller
当前集群中的主控节点是谁



